З дозволу розробника, Григорія Громка, на сайті «Плетиво» відкрито дзеркало ЄPython — одного з самих зручних інструментів для вивчення мови програмування Python. На ЄPython можна перейти за посиланням yepython.pletyvo.in.ua або через меню сайту (розділ «програмування»)
Сьогодні, в день Великодня давайте визначимо дату цього свята в різні роки.
Цю не саму тривіальну задачу намагалися розв’язати різними способами. Наприклад, в музеї Равенського собору в Італії знаходиться календар визначення дат Великодня на 95 років (532–626):

Фото з Вікіпедії
Ще та проблема цю графіку розтлумачити. Мабуть, саме так у 1800 році подумав Карл Фрідріх Гаусс і записав алгоритм визначення дня Великодня математично, формулами, при чому за старим і новим стилем. Через шість років його студент Петер Пауль Тіттель виявив помилку в алгоритмі щодо параметра p. Гаусс виправив цю помилку та подякував студенту за допомогу. Ще через 64 роки професор Базельського університету Герман Кінкелін поясненив кожен крок даного алгоритму. Ця все відомі факти, Вікіпедія досить непогано описує неспокійне життя церковників та математиків.
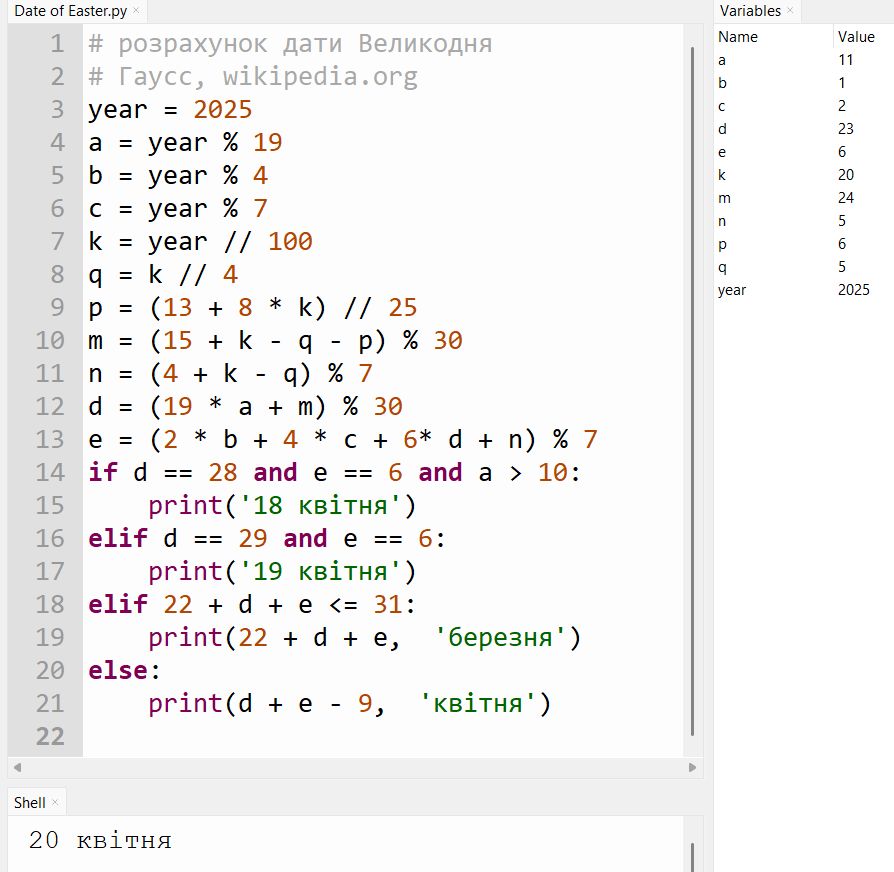
Як на мене, визначити дату Великодня за формулами Гаусса — це досить проста задача для програмістів-початківців. Тут і ділення націло і залишок від ділення і розгалуження.
Беремо алгоритм і пробуємо. У мене вийшло так, якщо цікаво.
Успіхів!
(перша частина тут)
(друга частина тут)
Частина 3.
Вважаю, що для навчання дітей дуже корисною є проста і зрозуміла візуалізація, якщо це можливо. Тоді концепції стають зрозумілими, а замудрені означення спокійно ігноруються. Саме в напрямку візуалізації пропоную розглянути один з варіантів опрацювання теми «Вкладені цикли».
Привела киця чотири кошеняти. От вони на базарі, сидять в рядок, один біля одного, дивляться світ. Підходимо, питаємо дозволу. Гладимо першого, кажемо що він класний, гладимо другого, кажемо що він класний, ну і так всіх. Що це у нас? Цикл. Ну, нехай цикл. Скільки разів повторюється? Чотири ж, бо кошенят чотири! А що саме повторюємо? Погладити кошенятку і сказати що він класний. Що-що вчитель каже? Ітерації тіла циклу? Та нехай каже, воно незрозуміло, але дуже солідно, може йому так треба для зарплати. А нам головне — це щоб всіх чотирьох кошенят і погладити і похвалити.
А от вкладені цикли. Близькі родичи сферичного коня у вакуумі. Для певної кількості учнів це складна штука, але для тих, хто хоче розібратися, як на мене, є прекрасна і візуально зрозуміла штука — світлодіодна матриця.
Ось така:

Ну і дешевий котролер для неї, той самий що був вже описаний в попередніх частинах.
Тут і з координатами дуже легко можна розібратися. Бо визначив координати — пару кліків мишки — і на окремому електронному пристрої бачиш результат. В другій частині нашого циклу статей про це вже писалося.
І з циклами просто зрозуміти. Хочешь — запалюй світлодіоди по черзі, всі тридцять два, і буде тобі один запалений рядок. А як лінуєшся — то можна циклом. Ось так:
for (int x = 0; x <= 31; x++) {
matrix.drawPixel(x, 1, HIGH);
matrix.write();
}
А як всі рядки запалити по черзі? Можна вручну 256 штук запалити, а можна простіше, вкладеними циклами. А щоб гарніше було, то після запалення кожного ще й невеличку паузу робити:
for (int y = 0; y <= 7; y++) {
for (int x = 0; x <= 31; x++) {
matrix.drawPixel(x, y, HIGH);
matrix.write();
delay(30);
}
}
І тоді можна подивитися на результат. Ось:
А як можна не зліва-направо, а в зворотному напрямку? А не рядками, а стовбчиками?
Можна скачати архів, в якому проєкт-приклад зі всіма необхідними бібліотеками, і далі гратися, пробувати. Ось трохи вправ на цю тему:
Якщо хочете повторити, то успіхів! Бо недорого, нескладно і зрозуміло. А ще можна колись буде сказати якимсь дітям: «Да я ще в школі кодив контролери з матрицями в студії!». Воно, звичайно, буде незрозуміло, але дуже солідно.
В українській пунктуації застосовують
круглі, або заокруглені, ( ),
квадратні [ ]
і кутові, або ламані, < > дужки
Епіграф з чудової книжки, що зветься «Український правопис». Чинна редакція 2019 року містить 393 сторінки і безкоштовно лежить на сайті МОН. В pdf файлі є текстовий шар, відповідно, працює пошук. Прекрасна книжка для розвіювання власних синтаксично-пунктуаційних ілюзій, рекомендую.
І саме про дужки наразі буде задача. Про круглі. На сайті basecamp.eolymp.com коефіцієнт прийняття задачі наразі складає 37% при 12к відправлень.
Задача «Дужкові послідовності».
https://basecamp.eolymp.com/uk/problems/5327
Умова:
Дужкова послідовність - це правильний арифметичний вираз, з якого видалили усі числа та знаки. Наприклад,
1+(((2+3)+5)+(3+4))→((())())
Вхідні дані
Задано послідовність з відткриваючих та закриваючих дужок довжиною не більше 4⋅106.
Вихідні дані
Виведіть "YES" якщо дужкова послідовність правильна та "NO" інакше.
Приклади
Вхідні дані #1
((())())
Відповідь #1
YES
Вхідні дані #2
(()
Відповідь #2
NO
Для успішного розв’язання задачі пропоную сформулювати умови правильної послідовності. Це через те, що тестові приклади підібрані так, що можуть трохи заплутати.
Чому в другому прикладі послідовність неправильна і виводиться «NO»? Через те, що кількість відкритих дужок не дорівнює кількості закритих дужок. Давайте запишемо цю очевидну умову червоним кольором:
У правильній послідовності кількість відкритих дужок дорівнює кількості закритих дужок.
Якщо проаналізувати приклад #1, то кількість відкритих і закритих дужок однакова. І програмісту початківцю може здатися, що умова, яка записана червоним кольором – єдина. І програміст-початківець пише щось на кшталт
s = input()
if s.count('(') == s.count(')'):
print('YES')
else:
print('NO')
За такий код сайт eolymp дає 96 балів зі 100. Якщо це – олімпіада з програмування, то це чимало, можна порадіти і поїсти чесно заробленого шоколаду. А якщо це випробування для прийому на роботу зі заблокованим штучним інтелектом, то треба шукати ще якісь умови правильної послідовності.
Пропоную ще один, мій приклад, що нам допоможе:
Вхідні дані #3
)(
Відповідь #2
NO
Кількість дужок співпадає, але бачимо, що існує, як мінімум, ще одна умова правильної послідовності. Давайте її сформулюємо знову червоним текстом:
При перегляді послідовності зліва направо кількість закритих дужок жодного разу не може перевищувати кількість відкритих дужок.
Тепер давайте спробуємо написати код, що враховує вже дві умови. Якщо програміст вміє, можна використати регулярні вирази або ще щось гарне. А якщо треба швидко і просто, то можна скористатися циклом і розгалуженням.
Логіка змінних:
t - текстова послідовність
v – кількість відкритих дужок
z – кількість закритих дужок
x – елемент текстової послідовності, що наразі аналізується
f – прапорець (flag), що підніметься якщо станеться ситуація, коли закритих дужок більше відкритих, по замовчуванню прапорець опущений (False). Якщо прапорець піднявся, то не варто продовжувати дослідження текстової послідовності, все одно вона неправильна.
t = input()
v = 0
z = 0
f = False
for x in t:
if x == '(':
v += 1
else:
if v > z:
z += 1
else:
f = True
break
if not f and v == z:
print('YES')
else:
print('NO')
Розглянемо задачу «Молоко та пиріжок»
https://basecamp.eolymp.com/uk/problems/7365
Учням першого класу призначають додаткову склянку молока та пиріжок, якщо першокласник важить менше 30 кг. В перших класах школи навчається n учнів. Склянка молока має об'єм 200 мл, а замовлені упаковки молока – 0,9 л. Визначити кількість додаткових пакетів молока та пиріжків, необхідних щодня.
Вхідні дані
У першому рядку задано ціле число n (0 < n ≤ 100). У наступному рядку знаходяться n додатних дійсних чисел – маси кожного першокласника.
Вихідні дані
В одному рядку вивести два цілих числа - кількість додаткових пакетів молока та пиріжків, необхідних щодня.
Приклади
Вхідні дані #1
8
30 27 31 25 32 29 25 30
Відповідь #1
1 4
Вхідні дані #2
30
21.5 36 30 35 22.5 39 45 20.7 38 35 20 24 36 23 20.9 22 21 30 38 33 30 37 31.6 25 32 29 35.8 40 28.9 25
Відповідь #2
3 13
На старій версії сайту eolymp.com було вказано автора задачі: sveta_p і вказано, що задача була на ІІ етапі Всеукраїнської олімпіади з інформатики.
Я запропонував цю задачу на i7-гуртку Святославу Поліщуку в якості розминки навіть не мізків, а пальців. Він її взяв в роботу, сидить, працює.
Я поки подивився свій розв’язок. Ще на етапі введення даних обираю всіх «легких» першокласників. На кожного з них розраховую по окремому додатковому пиріжку. З молоком схожа історія, обираю скільки треба всього мілілітрів додаткового молока і рахую скільки це буде пакетів з округленням в більшу сторону. Все логічно. Наприклад, так:
from math import ceil
input()
lightweights = [x for x in input().split() if float(x) < 30]
count_lightweights = len(lightweights)
milk = ceil(count_lightweights * 200 / 900)
pie = count_lightweights
print(milk, pie)
Цей розв’язок проходить всі тести, зарахований на 100%
Через деякий час Святослав здивовано каже, що у нього задача сайтом eolimp приймається лише на 82%, не проходить два тести, він не бачить проблему і пропонує переглянути його код разом. Тут була моя черга здивуватися, що неодноразовий призер обласної олімпіади не здає зовсім розминочну задачу.
Ось код Святослава:
from math import ceil
portion = int(input())
extra_portion = len([x for x in input().split() if float(x) < 30])
print(ceil((200 * (portion + extra_portion)) / 900) - ceil((200 * portion) / 900), extra_portion)
Тут стає зрозуміло, що його рішення дійсно правильне, а у мене – логічна помилка, як і у авторів тестів на сайті. Святослав, познайомившись з моїм рішенням цілком справедливо зауважів, що я для додаткових порцій молока завжди відкриваю новий пакет. Але може бути така ситуація, коли цього зовсім не треба робити.
Наприклад, у нас п’ять першокласників і один з них – легкий. Тому в моїй версії я видаю всім по 200 мл. молока. Це 1000 мл. Так як у нас в пакеті по 900 мл. згідно умови, то я відкриваю два пакета і пригощаю всіх. В другому пакеті залишається від цього молокопиття ще 800 мл. молока. Моя версія програми це молоко викидає (а може таємно краде і випиває) і для додаткової сесії, для «легких» учнів, відкриває новий пакет молока, з якого бере додатково потрібні 200 мл. В результаті – при наявності «легких» учнів моя програма завжди бере додатковий пакет, а програма Святослава вчила логіку і математику, вона нічого не викидає, вона все обліковує.
Трохи гріє душу факт, що судячи по тестам, Святослав переграв не лише мене, а і авторів олімпіадної задачі )) Молодець, що тут додати…
Дякую Святославу Поліщуку за код і довзіл його цитування в даній статті.
Сподобалася історія? Приходьте ще )
Подивився відомий американський науково-фантастичний психологічний серіал-трилер «Поділ» (Severance). Кіно відоме, має високий рейтинг на IMDB (8.7 з 10 при 257 тис. голосів), багато видань назвали його одним з найкращих серіалів 2022 року, на 74-й церемонії вручення премії «Еммі» серіал отримав 7 номінацій. Існує професійний україномовний переклад. В Німеччині і Франції серіал маркований як 12+, Ізраїль і Мексика визначають його як 18+. Дистриб’ютором серіалу є компанія Apple.
Щодо кіна, то питання окреме, мене зацікавила ідея. Ви приходите влаштовуватися на роботу, де є «поділ». Це означає, що ви погоджуєтесь на хірургічну операцію, де вам в голову вставляють невеличкий електронний пристрій. І все це заради того, щоб чітко розділити вашу роботу і ваше життя. На роботі ви не будете знати і пам’ятати нічого з вашого реального життя, лише робота. Коли робочий день завершений і ви вийдете з роботи, то не будете тягнути з собою робочі хвилювання, проблеми і переживання. Це буде Ваше абсолютно вільне від роботи життя. Повне розділення.
Вчительська робота має свої емоційні особливості і серйозні деформаційні ризики. Не раз читав думки вчителів про те, що робота займає море часу і сил вдома, що витягує на себе занадто велику частину звичайного життя. Цікаво, а при наявності реальної можливості, багато вчителів погодилися би на «поділ»? Відпрацював, вийшов зі школи — і вільний.

Фото звідси: https://www.imdb.com/title/tt11280740/mediaviewer/rm1255935745/?ref_=ttmi_mi_9

Воно ще молоде, а вже яке хитре! ))
Ви помиітили, що про спілкування зі AI все менше шуткують? І ця відповідь не така вже лінійна.
До речі, мої учні помітили що Deepseek використовує багато смайлів…

{kind=link}