Чудово, коли все чітко, як домовлялися. Ви купили квиток у застосунку, гроші з картки без проблем списалися. В потрібний час ви прийшли на перон, сіли в потяг, що стоїть саме на цьому пероні. Ваше місце у вагоні ніхто не зайняв і потяг вчасно приїхав до пункту призначення. Все чітко і надійно — як у німців. Чудово, так? До речі, а хто вам сказав, що в Deutsche Bahn завжди саме так? Хтось казав? І ви от просто так наївно та безкоштовно повірили? )
Погодьтесь, у реальних системах часто виникає багато проблемних ситуацій. Частину з них розробники передбачають і закладають відповідні алгоритми обробки, частину виловлюють при тестуваннях, решта дістається службам підтримки.
Якщо ми говоримо про формулювання умови в програмуванні, то програмісти хочуть щоб лаконічно та однозначно. Нічого зайвого, нічого такого, що можна зрозуміти по-різному. Але сьогодні ми розв’язуємо задачу з «поганою» умовою. Де купа зайвих деталей, кольоровий навоз та екстравагантний президент Бананової республіки. Але то реальне життя, а не чітка стерильність професійних авторів олімпіадних батлів.
Задача: «Кольоровий дощ»
https://basecamp.eolymp.com/uk/problems/994
У Банановій республіці дуже багато пагорбів, з'єднаних мостами. На хімічному заводі відбулась аварія, у результаті чого випарувалось експериментальне добриво "зован". На наступний день випав кольоровий дощ, причому він пройшов лише над пагорбами. У деяких місцях падали червоні каплі, у деяких - сині, а в інших - зелені, у результаті чого пагорби стали відповідного кольору. Президенту Бананової республіки це сподобалось, але він забажав пофарбувати мости між вершинами пагорбів так, щоб мости були пофарбовані у колір пагорбів, які вони з'єднують. На жаль, якщо пагорби різного кольору, то пофарбувати міст таким чином не вдасться. Порахуйте кількість таких "не гарних" мостів.
Вхідні дані
У першому рядку записано кількість пагорбів n (0 < n ≤ 100). Далі йде матриця суміжності, яка описує наявність мостів між пагорбами (1-міст є, 0-немає). В останньому рядку записано n чисел, які позначають колір пагорбів: 1 - червоний; 2 - синій; 3 - зелений.
Вихідні дані
Вивести кількість "не гарних" мостів.
(фото до задачі з сайту basecamp.eolymp.com)
Приклади
Вхідні дані #1
7
0 1 0 0 0 1 1
1 0 1 0 0 0 0
0 1 0 0 1 1 0
0 0 0 0 0 0 0
0 0 1 0 0 1 0
1 0 1 0 1 0 0
1 0 0 0 0 0 0
1 1 1 1 1 3 3
Відповідь #1
4
Незважаючи на фото в умові, з якого на нас дивиться граф, незважаючи на двомірну матрицю, яку не всі діти люблять, задача, погодьтесь, нескладна. Записуємо матрицю суміжності у двовимірний список а список кольорів також у відповідний список. Далі — нескладний аналіз.
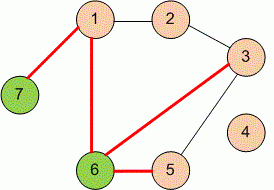
Повернемося до тестового прикладу. Згідно матриці суміжності і малюнку бачимо, що перший пагорб має мости з другим, шостим і сьомим пагорбом. Згідно умови, перший пагорб після кольорового дощу став червоний (1), другий – червоний (1), шостий – зелений (3), сьомий – також зелений(3). «Негарний» міст — це коли кольори пагорбів по його сторонах мають різний колір. Тому від першого пагорбу відходять два «негарних» мости 1-6, та 1-7.
Якщо ми опрацюємо таким чином всі пагорби, ми визначимо кількість «негарних» мостів. Звичайно, результат треба буде поділити на два, бо «негарний» міст 1-6 — це той самий міст, що і 6-1. Ось один з варіантів коду:
n = int(input())
m = []
bad_bridge = 0
for row in range(n):
m.append([int(element) for element in input().split()])
colors = [int(i) for i in input().split()]
for i in range(n):
for j in range(n):
if m[i][j]==1 and colors[i] != colors[j]:
bad_bridge += 1
print(bad_bridge // 2)
Все добре, але цей код здає задачу лише на 10%. Чому? Тому що специфічно написана умова. Зверніть увагу на тестовий приклад. Бачите після матриці суміжності пустий рядок? Про нього нема жодного слова в умові, але він є в тестовому прикладі. Я червоним кольором виділю рядок, який треба включити в програму:
n = int(input())
m = []
bad_bridge = 0
for row in range(n):
m.append([int(element) for element in input().split()])
input()
colors = [int(i) for i in input().split()]
for i in range(n):
for j in range(n):
if m[i][j]==1 and colors[i] != colors[j]:
bad_bridge += 1
print(bad_bridge // 2)
І от тепер задача буде прийнята системою на 100%.
Можна по різному це оцінювати. Формально, нам про необхідність пустого рядка у вхідних даних повідомили в тестовому прикладі, який є частиною умови. Але в умові, мабуть, варто про це писати текстом. Чи ні? Ви самостійно можете визначите власне відношення до такої ситуації. Чи варто учням-школярам давати такі задачі? А тим учням, що збираються бути айтішниками? Розв’язання таких задач сприяє розвитку критичного мислення? Купа філософських питань, відповіді на які я залишаю кожному з тих, хто сюди дочитав. Як таке відчуваєте саме Ви?
Анатолій Анатолійович
липень 2025
Сьогодні вкотре запрошую поговорити про красу. Хтось заради краси малює, хтось шукає красу в музиці, а в чому може бути краса у програмістів? Що може бути такого для програміста гарного, або, хоча б, прикольного?
Давайте розглянемо задачу в тему:
Маршрутне таксі
https://basecamp.eolymp.com/uk/problems/7410
У годину пік на зупинку одночасно під'їхали три маршрутних таксі, які слідують по одному маршруту, в які тут же набилися пасажири. Водії виявили, що кількість людей у різних маршрутках різна, і вирішили пересадити частину пасажирів так, щоб у кожній маршрутці було порівну пасажирів. Потрібно визначити, яку найменшу кількість пасажирів доведеться при цьому пересадити.
Вхідні дані
Три натуральних числа, що не перевищують 100 - кількості пасажирів у першій, другій і третій маршрутках відповідно.
Вихідні дані
Виведіть одне число - найменшу кількість пасажирів, яку потрібно пересадити. Якщо це неможливо, виведіть слово IMPOSSIBLE (великими літерами).
Приклади
Вхідні дані #1
1 2 3
Відповідь #1
1
Пропоную відразу розібратися, коли неможливо буде рівномірно розподілити пасажирів по маршрутках. Така ситуація виникне, коли загальна кількість пасажирів у всіх маршрутках не буде націло ділитися на три.
В інших випадках пересадити пасажирів можна. Можна визначити для початку, скільки пасажирів повинно бути після пересадки в кожній маршрутці — кількість всіх пасажирів поділити на три.
Далі по кожній маршрутці знайти кількість людей, які повинно вийти з кожної маршрутки або зайти в неї. Скористаємся модулем і врахуємо, що людина, що вийшла з однієї маршрутки, зайшла в іншу і при такому підході врахована двічі. Ось як може виглядати код:
a, b, c = map(int, input().split())
if (a + b + c) % 3 != 0:
print('IMPOSSIBLE')
else:
avg = (a + b + c) // 3
print((abs(avg - a) + abs(avg - b) + abs(avg - c)) // 2)
Це гарно? Мабуть, так. І вчителька математики не проти. Але чи існують ще гарні рішення?
А якщо прийде програміст Петрик, що проспав урок про модулі і скаже, що двічі рахувати пасажирів негарно, а він без усіляких модулів вирішив рахувати лише тих, хто виходить з маршруток для пересадки? Ось так:
counts = [int(x) for x in input().split()]
if sum(counts) % 3 != 0:
print('IMPOSSIBLE')
else:
avg = sum(counts) // 3
move = 0
for count in counts:
if count > avg:
move += count - avg
print(move)
А от це — гарно? Здається і це гарно, навіть якщо вчителька математики буде вважати, що не треба придумувати дурню і їсти картоплю черпаком.
А яких з кодів гарніший? А який — швидший? А який більше подобається саме Вам, шановний читач? А чому? Який код гарніший саме для Вас? Бо ми ж сьогодні — про красу.
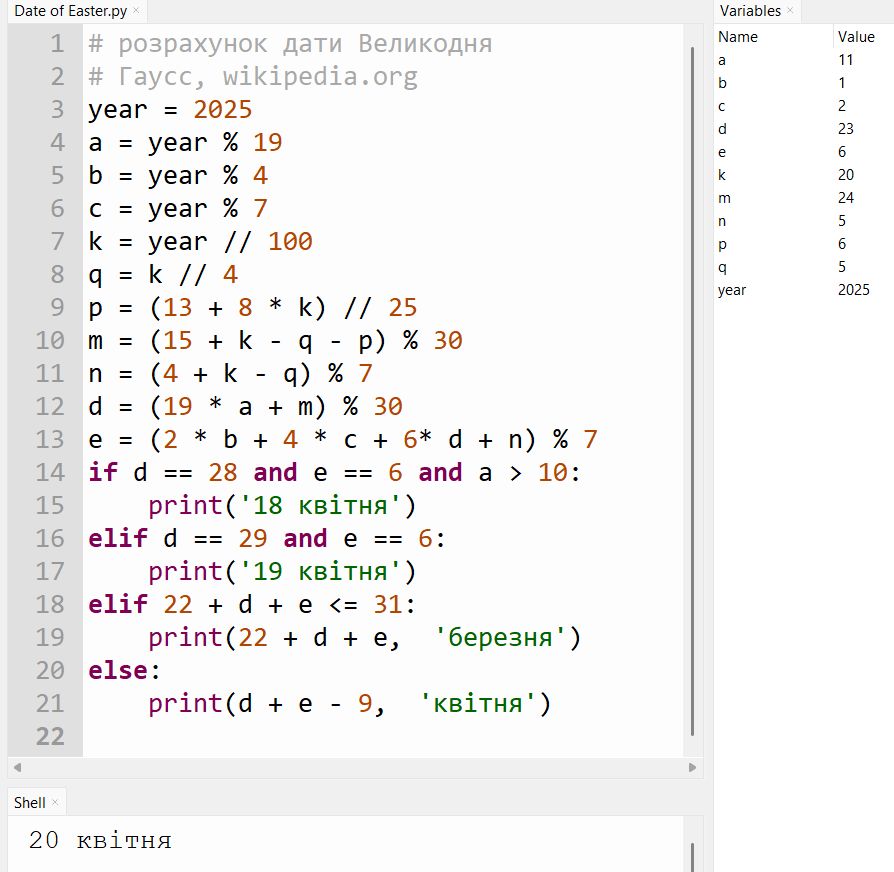
Сьогодні, в день Великодня давайте визначимо дату цього свята в різні роки.
Цю не саму тривіальну задачу намагалися розв’язати різними способами. Наприклад, в музеї Равенського собору в Італії знаходиться календар визначення дат Великодня на 95 років (532–626):

Фото з Вікіпедії
Ще та проблема цю графіку розтлумачити. Мабуть, саме так у 1800 році подумав Карл Фрідріх Гаусс і записав алгоритм визначення дня Великодня математично, формулами, при чому за старим і новим стилем. Через шість років його студент Петер Пауль Тіттель виявив помилку в алгоритмі щодо параметра p. Гаусс виправив цю помилку та подякував студенту за допомогу. Ще через 64 роки професор Базельського університету Герман Кінкелін поясненив кожен крок даного алгоритму. Ця все відомі факти, Вікіпедія досить непогано описує неспокійне життя церковників та математиків.
Як на мене, визначити дату Великодня за формулами Гаусса — це досить проста задача для програмістів-початківців. Тут і ділення націло і залишок від ділення і розгалуження.
Беремо алгоритм і пробуємо. У мене вийшло так, якщо цікаво.
Успіхів!
В українській пунктуації застосовують
круглі, або заокруглені, ( ),
квадратні [ ]
і кутові, або ламані, < > дужки
Епіграф з чудової книжки, що зветься «Український правопис». Чинна редакція 2019 року містить 393 сторінки і безкоштовно лежить на сайті МОН. В pdf файлі є текстовий шар, відповідно, працює пошук. Прекрасна книжка для розвіювання власних синтаксично-пунктуаційних ілюзій, рекомендую.
І саме про дужки наразі буде задача. Про круглі. На сайті basecamp.eolymp.com коефіцієнт прийняття задачі наразі складає 37% при 12к відправлень.
Задача «Дужкові послідовності».
https://basecamp.eolymp.com/uk/problems/5327
Умова:
Дужкова послідовність - це правильний арифметичний вираз, з якого видалили усі числа та знаки. Наприклад,
1+(((2+3)+5)+(3+4))→((())())
Вхідні дані
Задано послідовність з відткриваючих та закриваючих дужок довжиною не більше 4⋅106.
Вихідні дані
Виведіть "YES" якщо дужкова послідовність правильна та "NO" інакше.
Приклади
Вхідні дані #1
((())())
Відповідь #1
YES
Вхідні дані #2
(()
Відповідь #2
NO
Для успішного розв’язання задачі пропоную сформулювати умови правильної послідовності. Це через те, що тестові приклади підібрані так, що можуть трохи заплутати.
Чому в другому прикладі послідовність неправильна і виводиться «NO»? Через те, що кількість відкритих дужок не дорівнює кількості закритих дужок. Давайте запишемо цю очевидну умову червоним кольором:
У правильній послідовності кількість відкритих дужок дорівнює кількості закритих дужок.
Якщо проаналізувати приклад #1, то кількість відкритих і закритих дужок однакова. І програмісту початківцю може здатися, що умова, яка записана червоним кольором – єдина. І програміст-початківець пише щось на кшталт
s = input()
if s.count('(') == s.count(')'):
print('YES')
else:
print('NO')
За такий код сайт eolymp дає 96 балів зі 100. Якщо це – олімпіада з програмування, то це чимало, можна порадіти і поїсти чесно заробленого шоколаду. А якщо це випробування для прийому на роботу зі заблокованим штучним інтелектом, то треба шукати ще якісь умови правильної послідовності.
Пропоную ще один, мій приклад, що нам допоможе:
Вхідні дані #3
)(
Відповідь #2
NO
Кількість дужок співпадає, але бачимо, що існує, як мінімум, ще одна умова правильної послідовності. Давайте її сформулюємо знову червоним текстом:
При перегляді послідовності зліва направо кількість закритих дужок жодного разу не може перевищувати кількість відкритих дужок.
Тепер давайте спробуємо написати код, що враховує вже дві умови. Якщо програміст вміє, можна використати регулярні вирази або ще щось гарне. А якщо треба швидко і просто, то можна скористатися циклом і розгалуженням.
Логіка змінних:
t - текстова послідовність
v – кількість відкритих дужок
z – кількість закритих дужок
x – елемент текстової послідовності, що наразі аналізується
f – прапорець (flag), що підніметься якщо станеться ситуація, коли закритих дужок більше відкритих, по замовчуванню прапорець опущений (False). Якщо прапорець піднявся, то не варто продовжувати дослідження текстової послідовності, все одно вона неправильна.
t = input()
v = 0
z = 0
f = False
for x in t:
if x == '(':
v += 1
else:
if v > z:
z += 1
else:
f = True
break
if not f and v == z:
print('YES')
else:
print('NO')
Розглянемо задачу «Молоко та пиріжок»
https://basecamp.eolymp.com/uk/problems/7365
Учням першого класу призначають додаткову склянку молока та пиріжок, якщо першокласник важить менше 30 кг. В перших класах школи навчається n учнів. Склянка молока має об'єм 200 мл, а замовлені упаковки молока – 0,9 л. Визначити кількість додаткових пакетів молока та пиріжків, необхідних щодня.
Вхідні дані
У першому рядку задано ціле число n (0 < n ≤ 100). У наступному рядку знаходяться n додатних дійсних чисел – маси кожного першокласника.
Вихідні дані
В одному рядку вивести два цілих числа - кількість додаткових пакетів молока та пиріжків, необхідних щодня.
Приклади
Вхідні дані #1
8
30 27 31 25 32 29 25 30
Відповідь #1
1 4
Вхідні дані #2
30
21.5 36 30 35 22.5 39 45 20.7 38 35 20 24 36 23 20.9 22 21 30 38 33 30 37 31.6 25 32 29 35.8 40 28.9 25
Відповідь #2
3 13
На старій версії сайту eolymp.com було вказано автора задачі: sveta_p і вказано, що задача була на ІІ етапі Всеукраїнської олімпіади з інформатики.
Я запропонував цю задачу на i7-гуртку Святославу Поліщуку в якості розминки навіть не мізків, а пальців. Він її взяв в роботу, сидить, працює.
Я поки подивився свій розв’язок. Ще на етапі введення даних обираю всіх «легких» першокласників. На кожного з них розраховую по окремому додатковому пиріжку. З молоком схожа історія, обираю скільки треба всього мілілітрів додаткового молока і рахую скільки це буде пакетів з округленням в більшу сторону. Все логічно. Наприклад, так:
from math import ceil
input()
lightweights = [x for x in input().split() if float(x) < 30]
count_lightweights = len(lightweights)
milk = ceil(count_lightweights * 200 / 900)
pie = count_lightweights
print(milk, pie)
Цей розв’язок проходить всі тести, зарахований на 100%
Через деякий час Святослав здивовано каже, що у нього задача сайтом eolimp приймається лише на 82%, не проходить два тести, він не бачить проблему і пропонує переглянути його код разом. Тут була моя черга здивуватися, що неодноразовий призер обласної олімпіади не здає зовсім розминочну задачу.
Ось код Святослава:
from math import ceil
portion = int(input())
extra_portion = len([x for x in input().split() if float(x) < 30])
print(ceil((200 * (portion + extra_portion)) / 900) - ceil((200 * portion) / 900), extra_portion)
Тут стає зрозуміло, що його рішення дійсно правильне, а у мене – логічна помилка, як і у авторів тестів на сайті. Святослав, познайомившись з моїм рішенням цілком справедливо зауважів, що я для додаткових порцій молока завжди відкриваю новий пакет. Але може бути така ситуація, коли цього зовсім не треба робити.
Наприклад, у нас п’ять першокласників і один з них – легкий. Тому в моїй версії я видаю всім по 200 мл. молока. Це 1000 мл. Так як у нас в пакеті по 900 мл. згідно умови, то я відкриваю два пакета і пригощаю всіх. В другому пакеті залишається від цього молокопиття ще 800 мл. молока. Моя версія програми це молоко викидає (а може таємно краде і випиває) і для додаткової сесії, для «легких» учнів, відкриває новий пакет молока, з якого бере додатково потрібні 200 мл. В результаті – при наявності «легких» учнів моя програма завжди бере додатковий пакет, а програма Святослава вчила логіку і математику, вона нічого не викидає, вона все обліковує.
Трохи гріє душу факт, що судячи по тестам, Святослав переграв не лише мене, а і авторів олімпіадної задачі )) Молодець, що тут додати…
Дякую Святославу Поліщуку за код і довзіл його цитування в даній статті.
Сподобалася історія? Приходьте ще )
{kind=link}