Вчителі — різні. Хтось зброджує бочку візії, яку потім намагається розлити по пляшках-концепціях. Хтось не довіряє такому підозрілому рівню абстракцій і шукає надійні шляхи практичної конкретики, хтось «йде по підручнику».
Як завжди, на «Плетиві» звертатимемо увагу на конкретне — й, можливо, цікаве.
В українському курсі шкільної інформатики є моделювання. І було б непогано, щоб учні розуміли, що це таке і для чого може згодитися. Щодо легального програмного забезпечення в цьому сегменті, то є Blender, Blockbench. Один зі світових лідерів у сфері моделювання — компанія Autodesk — має потужний програмний продукт Fusion, який для особистого некомерційного користування є безкоштовним.
Як на мене, для ознайомлення одним із найкращих варіантів є Tinkercad від того самого Autodesk, на «Плетиві» в червні 2023 року вже була стаття по Tinkercad. Особисто мені цей інструмент подобається тим, що він простий у використанні, дозволяє швидко розпочати розробку й отримувати результати.
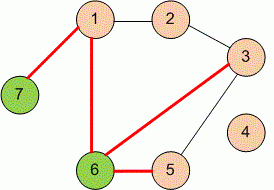
Як приклад, згадаю, як ми з учнями робили брелоки з власними іменами. Текст треба було «втопити» в брелок, щоб гострими краями він не рвав кишені. Впоралися швидко, було гамірно. Гарна ознака )) Як здати результат учителю? Та ми ж в єдиному електронному просторі! Учитель бачить роботи, розміщені в шкільних Tinkercad-акаунтах учнів.
Ось:

Це справді можна зробити весело й гамірно — всього за один урок. І це можна надрукувати на 3D-принтері в один колір, приклавши мінімум зусиль. Розроблену модель можна зберегти у форматі STL, який є стандартом для подальшого 3D-друку. Tinkercad, Blender, Fusion — усі вони підтримують збереження моделей у форматі STL. Тобто, за наявності 3D-принтера учні можуть отримати свої найкращі художні роботи у фізичному вигляді. Підготувати, надрукувати і подарувати їх, скажімо, Оленці.
Або давайте ускладнимо задачу й спробуємо надрукувати «втоплений текст» з обох сторін монетки. Нехай хлопчику Петрику подобаються дві дівчини — Аня і Маша, і він не може обрати, яку з них запросити на побачення. Замість того, щоб тихо собі позаздрити, він вирішив кинути монетку. Як рандом випаде — так нехай і буде. Петрик ще не в курсі, що це дурна ідея, а якщо дівчата про таку монетку дізнаються, то він автоматично буде винуватий глобально і у всьому. Але за кілька хвилин у Tinkercad Петрик робить таку монетку — на різні її сторони він втоплює імена дівчат, ось так:

Потім зберігає модель монетки у файл формату STL.
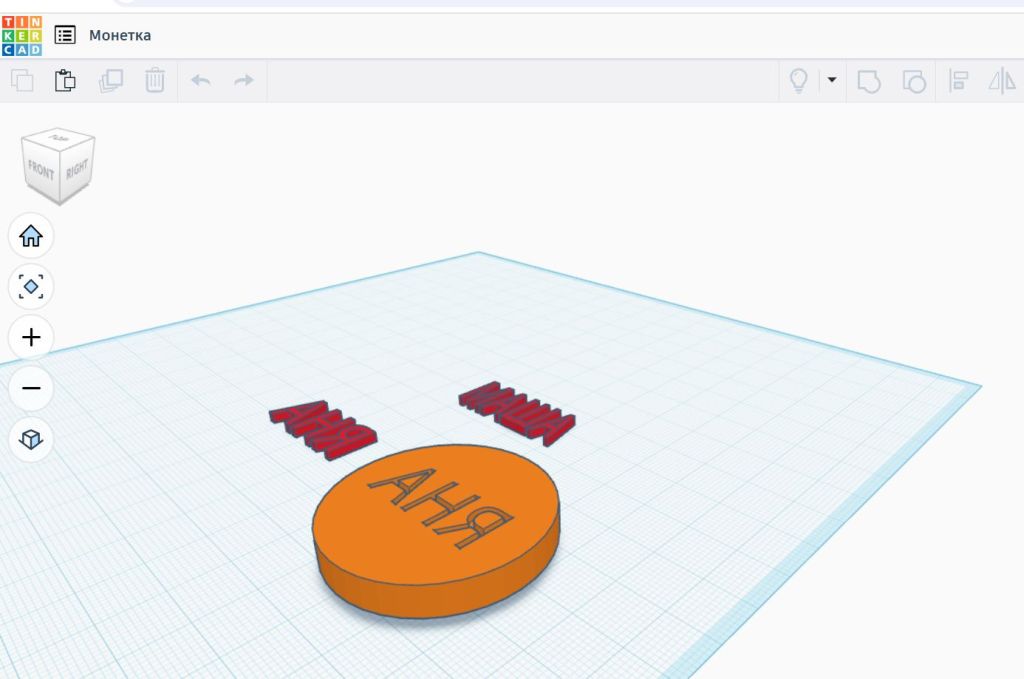
Наступним етапом Петрику потрібно підготувати потік команд для конкретного 3D-принтера (так званий G-code). Для цього потрібна будь-яка програма-слайсер. Він обирає одну з найвідоміших — OrcaSlicer, яка також безкоштовна. В інтернеті є безліч відео, як швидко отримати з файлу STL потрібний G-code на стандартних налаштуваннях, без занурення в технічні деталі.
В Петриковому експерименті на популярному пластику, що зветься PETG, програма-слайсер повідомила, що принтер надрукує таку монетку за 13 хвилин, витративши 1,52 метри пластикової нитки. Пластик, до речі, має «розумну» назву — філамент. Товщина нитки філамента зазвичай становить 1,75 мм.
Зберігаємо сформований слайсером G-сode на флешку, підключаємо флешку до 3D принтера, друкуємо. От, яка краса:


Тут цікаво інше. Зверху монетку легко друкувати: там, де не потрібно — принтер просто не видавлює пластик, і тому ім’я «Аня» ніби втоплене. А як бути з іншої сторони? Спочатку принтер у місцях букв імені «Маша» не видавлюватиме пластик — там утворяться пустоти. Але потім принтер має зробити монету суцільною. Як він тоді надрукує розплавленим пластиком суцільний шар поверх пустот? Давайте подивимось.

Отже, виходить, що принтер таки може друкувати поверх пустоти. Як саме — пошукайте в інтернеті. ))
І, мабуть, ви звернули увагу, що якість монети не така вже і чудова. Так і є. Якщо треба гарніше, то це вже ціле море деталей. Вибір філаменту, параметрів в програмі-слайсері. Вибір принтера і технології друку. Якісні вироби друкують на 3D-принтерах зовсім іншого рівня. Ось, наприклад, відомий принтер, який точно і якісно друкує моделі з полімерної смоли:
 Фото звідси
Фото звідси
Але для нашого Петрика це надто дорого, а свою монетку він уже отримав, використавши всього два програмні пакети — Tinkercad та OrcaSlicer, а також п’ять грамів філаменту типу PETG, який у роздріб коштує близько 400–500 гривень за кілограм. Звичайно, існують пластики різних типів, кольорів і цін.
Пластик PETG нормально експлуатується при температурах –40°C…+70°C, тому з нього можна робити не лише монети для Петрика, а наприклад, інформаційні таблички:

Ця яскрава табличка призначена допомогти людям знайти укриття. Моделювання виконано у Fusion. Далі — підготовка G-code в OrcaSlicer. Потім — жовтий пластик, прозорий акриловий ґрунт і чорна акрилова фарба.
Fusion — популярний пакет. По ньому легко знайти в Інтернеті уроки та курси. Якщо учень отримує задоволення від такої роботи і хоче розвиватися в цьому напрямку, це може стати ефективним стартом до професії. Інженер-конструктор — непогана професія, яка в майбутньому може принести учню непоганий шматок хліба з маслом.
Для творчих людей завжди є можливість спробувати зробити щось своє. Або знайти багато корисних чи художніх моделей на сайті printables.com.
Ось, наприклад, який гарний вовчик:
 Фото звідси
Фото звідси
Так, з printables.com можна безкоштовно скачати файл STL і в OrcaSlicer зробити G-code. До речі, в OrcaSlicer легко змінити розмір вовчика — зробити його більшим або меншим, якщо, наприклад, у вас обмаль пластику.
Ну і не менш важливе. Друкарі та 3D-принтери можуть дуже допомогти нашим військовим. В Україні є кілька проєктів, що об’єднують військових та друкарів. Найвідоміший з них – ДрукАрмія.

Коли на сайті ДрукАрмії реєструється військовий, він бачить великий каталог із кількасот позицій і може замовити пластикові вироби для свого підрозділу. Якщо деталі вже надруковані та є в наявності на складах ДрукАрмії, вони відправляються військовим. Якщо деталей немає — інженери розроблять STL-моделі, друкарі надрукують їх і надішлють кураторам для перевірки якості, після чого вироби також передаються військовим.
Якщо до ДрукАрмії долучається друкар, йому пропонують сотні виробів, які він може взяти в роботу, надрукувати й передати куратору. Друкар отримує вже готові STL файли, залишається зробити G-code під свій пластик і принтер — і друкуй. Виробництво, зазвичай, власним коштом. Пересилання «Новою Поштою» — також. На філамент друкарі збирають гроші де тільки можуть — зборами, конкурсами, розіграшами фігурок. Власними коштами, донатами колег, знайомих, тих, хто довіряє. З технічних питань ДрукАрмія має велике ком’юніті в Telegram, де підкажуть, якщо друк не виходить. Брак — не біда, а привід щось підправити. Отже, друкарю допоможуть технічною консультацією, дадуть можливість обрати деталь для роботи і дадуть адресу, куди відправити надруковане. Потім ще поставлять оцінку за якість друку.
Як то кажуть – мати доступ до 3D-принтера і не намагатися друкувати для військових — це непорядно.
Пам’ятаєте нашу рандомну монетку Петрика? Вона важить трохи більше п’яти грамів. Ось статистика роботи ДрукАрмії за 2024 і частину 2025 року з їхнього офіційного телеграм-каналу:
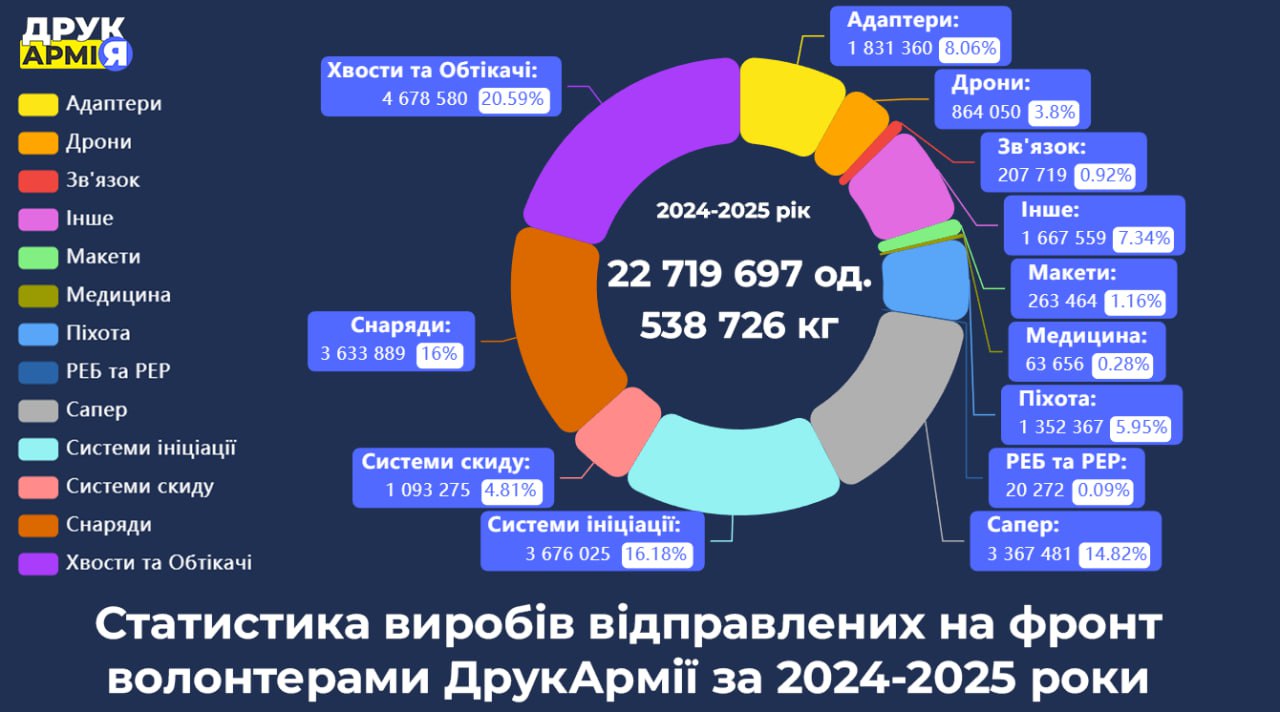
Як бачимо, ДрукАрмією менше ніж за два роки надруковано і відправлено військовим більше як 500 тон пластикових виробів. Але у внутрішніх повідомленнях на сайті ДрукАрмії пишуть про великі черги військових, що чекають.
От як працює один з друкарів-волонтерів:
До речі, велика бімба, що демонструє волонтер, друкується, мабуть, години чотири. Це все не так швидко, але дуже потрібно.
Комплект запчастин на один дрон коштує сьогодні 11-12 тисяч гривень. Дрон ще треба вміти якісно зібрати, щоб військові не ризикували життям і не переробляли. За ці кошти можна купити в Україні популярний 3D-принтер і поки він їде, зареєструватися на сайті ДрукАрмії та опрацювати розділ «Школа». ДрукАрмія і друкарі-експерти радять як перший принтер Bambu Lab A1 Mini вартістю до 11 тисяч гривень:

Якщо таких грошей немає, зазвичай до збору залучають знайомих, друзів і колег, з чітким поясненням, на що саме збираються кошти. Дехто знаходить гроші за кордоном. І якщо вдається придбати принтер, то вже за кілька днів друку можна отримати перші результати, яких чекають військові. Безумовно, треба розраховувати, що купувати треба ще і філамент.
Популярна думка, що кожен поважаючий себе друкар обов'язково є зареєстрований і працює в ДрукАрмії. Водночас час від часу чую про 3D-принтери, що стоять і припадають пилом. Мабуть тому, що люди біля них або не вміють або чужі. Адже на аматорському рівні цьому легко навчитися, і цього для початку цілком достатньо.
А ще знаю принтери, які купували вже під час війни саме для допомоги військовим — як за власні, так і за колективно зібрані кошти. І на філамент люди скидаються і на відправки. У тих місцях, де працюють небайдужі, і військовим надрукують і окремо куплять трохи пластику для друку табличок, вовчиків чи експериментів Петрика.
Розкажіть про ДрукАрмію знайомим військовим. І незнайомим теж. Далеко не всі захисники знають про таку можливість. А даремно — можливо, те, що їм потрібно, вже надруковано і чекає на складі. Наразі склади є не лише в Україні, хаби ДрукАрмії розгорнуто майже в 20 країнах Європи. Ось загальний алгоритм для військових:

Хтось встановлює друкувальні ферми на десятки принтерів, наймає персонал і купує пластик оптом. А у когось лише власні можливості і один доступний 3D-принтер. Але він працює. Бо чекають.
Анатолій Анатолійович,
липень, 2025
ps. Якщо Ви вважаєте статтю цікавою і вартою уваги, перешліть її, будь ласка, знайомим, друзям, військовим, активним колегам. Комусь це може стати у пригоді, а комусь — вкрай потрібною допомогою. Покликання: pletyvo.in.ua/3d